The third book of rationality
This is part 3 of 6 in my series of summaries. See this post for an introduction.
Interlude: The Power of Intelligence
Part III




Interlude: An Intuitive Explanation of Bayes’s
Theorem



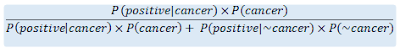


Interlude: The Power of Intelligence
OUR BRAINS ARE basically yucky lumps of slimy
grayish tissue. Aristotle thought the brain was an organ for cooling blood. The
brain doesn’t look like some of the
most powerful stuff in the universe, but it is the ultimate weapon and ultimate
defense.
Humans don’t have armored
shells, claws, or venoms like other animals. But we have machine guns, fighter
jets, and nuclear bombs. We can manipulate DNA. If you were alive when human
civilization began, you would not have predicted these things.
Such is the
power of intelligence and
creativity. The gray wet thing is the trick behind landing on the moon, curing
smallpox, and manufacturing computers. But people still don’t understand how
their brains work, so the power of intelligence seems less real, and harder to
imagine.
But the one trick works
anyway. The footprints are on the moon nonetheless. If you are ignorant about a
phenomenon, that is a fact about your state of mind, not the phenomenon. Intelligence
is as real as electricity. So if we could understand deeply enough, we could
create and shape that power – except it is far more powerful and dangerous than
electricity. One fell swoop could solve even such prosaic problems as obesity,
cancer, and aging. Don’t think that an Artificial Intelligence can’t do
anything interesting over the internet unless a human programmer builds it a
robot body.
›
Part III
The Machine in the Ghost
W
|
hy haven’t
we evolved to be more rational? To get a realistic picture of how and why our
minds execute their biological functions, this part cracks open the hood and
looks at how evolution works and how our brains work, with more precision. By
locating our minds within a larger space of goal-directed systems, we can
identify some peculiarities of human reasoning.
You are a mind, which means
you can make predictions and form plans, and even form, inside your mind, a picture of your whole mind. However, your mind
is implemented on a human brain, which despite its flexibility, can follow
patterns and routines for a lifetime without noticing that it is doing so.
These routines can have great consequences. A mental pattern that serves you
well is called “rationality”. But because of your ancestry, you are hard-wired
to exhibit certain species of irrationality. You are built on the echoes of
your ancestors’ struggles and victories.
We tend to think of our minds
in terms of mental categories (e.g. ideas, feelings) rather than physical
categories. Philosophers in the past have argued that minds and brains are
fundamentally distinct and separate phenomena. This is dualism, also known as
“the dogma of the Ghost in the Machine”. But even a modern scientific view
needs a precise overarching theory that predicts how the mind works, to avoid
making the same kinds of mistakes. Perhaps we can learn about ourselves from
inhuman mind-like systems/processes in evolutionary biology and artificial
intelligence (AI).
Yudkowsky is a decision theorist
who works on foundational issues in Artificial General Intelligence (AGI), the
theoretical study of domain-general problem-solving systems. His work in AI has
been a major driver behind his exploration of human rationality. Yudkowsky
predicts that in the long-run, AI will surpass humans in an “intelligence
explosion” (or “technological singularity”), which will likely result in social
upheaval. The term “Friendly AI” refers to research into techniques for
aligning AGI preferences with the preferences of humans. This is technically
difficult, because AI systems will learn and evolve over time, as will
circumstances and our desired responses to circumstances change – so we need to
give the program a utility function that remains harmless to humans dynamically.
Cognitive bias can interfere with our ability to forecast existential risks in
advance.
12
|
The Simple Math of Evolution
|
Knowing
the designer can tell you much about the design. This chapter is about the
dissonance and divergence between our hereditary history, our present-day
biology, and our ultimate aspirations. It will dig deeper than the
surface-level features of natural selection.
|
We humans tend to see “purpose” in the natural
world. But there is no “Evolution Fairy” with the prudential foresight to
design purposeful creatures. Rather, whatever happens is caused by genes’
effects on those genes’ frequency in the next generation. Thus foxes catch
rabbits, and rabbits evade foxes. We are simply the embodied history of which
organisms did in fact survive and reproduce. This doesn’t seem like it was
designed by the Judeo-Christian concept of one benevolent God. Evolution is
like an amoral blind idiot god – not like Jehovah, but like Azathoth (from H.P.
Lovecraft’s stories), burbling chaotically at the center of everything.
Evolution is awesomely powerful, unbelievably stupid, incredibly slow,
monomaniacally single-minded, irrevocably splintered in focus, blindly shortsighted,
and itself a completely accidental process.
The wonder of evolution is that despite being
stupid and inefficient, it works anyway. The first accidental replicator
(probably RNA) did not replicate gracefully, so don’t praise it too highly for
being a “wonderful designer” – that’s missing the point. Evolution doesn’t work
amazingly well, but that it works at all is the wonder: that a first
replicator could arise by pure accident in the primordial seas of Earth, and
that a brainless, mindless optimization process can produce complex designs by
working incrementally. But evolution is not a wonderfully intelligent designer
that we humans ought to imitate!
We have a definite picture of evolution’s
capabilities. Evolution is slow: it can take an allele thousands of generations
to become fixated in the gene pool, and complex adaptations take millions of
years. Evolution is sufficiently simpler than organic brains that we can
describe mathematically how slow and stupid it is. The formula for the number
of generations to fixation is 2ln(N)/s where N is the population size and (1+s)
is the fitness advantage of the gene, and the probability that a mutation
reaches fixation is 2s. For example, a gene conveying a 3% advantage would take
768 generations (on average) to reach universality among a population of
100,000 and have a 6% chance of fixating. By comparison, human technology seems
like magic.
Evolution is not invoked wherever
“reproduction” exists. Corporations or self-replicating nanodevices do not
“evolve” in the Darwinian sense because they don’t conform to Price’s Equation, which says that for
each generation, the change in average characteristic (e.g. a gene for height)
equals the covariance between the characteristic and its relative reproductive
fitness. It is practically impossible for complex adaptations to arise without
constant use. You need high-fidelity long-range heritability across the
generations, plus variance in reproduction, plus frequent death of old
generations to have enough cumulative selection pressure to produce complex
adaptations by evolution.
Contrary to common misconception, evolution
doesn’t optimize for species survival, but for allele frequency. Evolution
cares only about the inclusive fitness of genes relative to each other. Genes
that “harm” the species may outreproduce their alternative alleles. It is thus
possible to evolve to extinction, because individual competition can overcome
group selection pressures (for example see cancer cells). There are related
concepts like bystander apathy (not
helping someone because there are others around) and existential risk (species-level extinction threats which no-one is
fighting).
The group
selectionists (some pre-1960s biologists) had the romantic aesthetic idea
that individuals would voluntarily restrain reproduction in order to avoid
collapse of the predator-prey system, for the good of the species. They
expected evolution to do smart, nice things like they would do themselves.
Group selection is difficult to make work mathematically, and evolution doesn’t
usually do this sort of thing. So the biologists conducted a lab experiment
with insects. But Nature didn’t listen: it selected for individuals who cannibalize
others’ offspring! This case warns us not to anthropomorphize evolution.
Humans are good at arguing that almost any
optimization criterion suggests almost any policy. Natural selection optimizes only for inclusive genetic fitness – not politics or aesthetics. That is why
it’s a good case study to see the results of a monotone optimization criterion
(like that of evolution), to compare to human rationalizations of choices in a
complex society. Studying evolution lets us see an alien optimization process
and its consequences up close, and lets us see how optimizing for inclusive genetic
fitness does not require predators to restrain their breeding to live in
harmony with prey. Humans have trouble seeing what option a choice criterion really endorses.
A central principle of evolutionary science is
that we are adaptation-executors, not fitness-maximizers; and that is why the
consequences of having taste buds are different today than fifty thousand years
ago. Taste buds are an executing
adaptation because they are adapted to an ancestral environment where
calories were scarce, but that doesn’t mean that humans today would find a
cheeseburger distasteful. Purpose or meaning exists in the mind of a designer,
not the tool itself. Hence the real-world operations of the tool won’t
necessarily match the expectations.
Our brains are reproductive organs too, and the
evolutionary cause of anger or lust is that ancestors with them reproduced
more. Humans have the ability for thought and emotion for the same reason that
birds have wings: they are adaptations selected for by evolution. However, this
does not mean that the cognitive purpose of anger is to have
children! Our neural circuitry has no sense of “inclusive genetic fitness”. The
reason why a particular person was angry at a particular thing is separate! The
cause, shape, meaning, and consequence of an adaptation are all separate
things. Evolutionary psychology demands careful nitpicking of facts.
We should use language that separates out
evolutionary reasons for behavior and clearly labels them. Draw a clear boundary between psychological events in a brain
(cognitive reasons for behavior), and historical evolutionary causes! We should
be less cynical about executing adaptations to do X, and more cynical about
doing X because people (consciously or subconsciously) expect it to signal Y.
For example, it would be disturbing if parents in general showed no grief for
the loss of a child who they consciously believed to be sterile.
In a 1989 experiment, Canadian
adults who imagined their expected grief of losing a child of varying age showed
a strong correlation (0.92) with the reproductive-potential curve of the !Kung
hunter-gatherers – in other words, with the future reproductive success rate of
children at that age in the tribe. This shows that the parental grief adaptation
continues executing as if the parent were living in a !Kung tribe rather than
Canada. Although the grief was created by evolution, it is not about the children’s reproductive value!
Parents care about children for their own sake.
The modern world contains things that match our
desires more strongly than anything in the evolutionary environment. Candy
bars, supermodels, and video games are superstimuli.
As of 2007, at least three people have died by playing online games non-stop.
Superstimuli exist as a side-effect of evolution. A candy bar corresponds
overwhelmingly well to the food characteristics of sugar and fat that were
healthy in the environment of evolutionary adaptedness. Today the market
incentive is to supply us with more temptation, even as we suffer harmful
consequences. Thus, superstimuli are likely to get worse. This doesn’t
necessarily mean the government can fix it – but it’s still an issue.
Why did evolution create brains that would
invent condoms? Because the blind idiot god wasn’t smart enough to program a
concept of “inclusive genetic fitness” into us, so its one pure utility
function splintered into a thousand shards of desire. We don’t want to optimize
for genetic fitness, but we want to optimize for other things. Human values are
complex. We care about sex, cookies, dancing, music, chocolate, and learning
out of curiosity. At some point we evolved tastes for novelty, complexity,
elegance, and challenge. The first protein computers (brains) had to use
short-term reinforcement learning to reproduce, but now we use intelligence to
get the same reinforcers. With our tastes we judge the blind idiot god’s
monomaniacal focus as aesthetically unsatisfying. We don’t have to fill the
future with maximally-efficient replicators, and it would be boring anyway.
Being a thousand shards of desire isn’t always fun, but at least it’s not
boring.
›
13
|
Fragile Purposes
|
This
chapter abstracts from human cognition and evolution to the idea of minds and
goal-directed systems at their most general. It also explains Yudkowsky’s
general approach to philosophy and the science of rationality, which is
strongly informed by his work in AI.
|
What does a belief that an agent is intelligent
look like, and what predictions does it make? For optimization processes (like
Artificial Intelligence or natural selection) we can know the final outcomes
without being able to predict the exact next action or intermediary steps,
because we know the target toward which they are trying to steer the future.
For example, you don’t know which moves Garry Kasparov will make in a chess
game, yet your belief that Kasparov is a better chess player than his opponent
tells you to anticipate that Kasparov will win (because you understand his goals).
Complex adaptations in a sexually-reproducing
species are universal, and this applies to the human brain. We share universal
psychological
properties that let us tell stories, laugh, cry, keep secrets, make promises
and be sexually jealous, and so on. All human beings employ nearly identical
facial expressions and share the emotions of joy, sadness, fear, disgust, anger
and surprise. We take these for granted. But thus we naively expect all other
minds to work like ours, which causes problems when trying to predict the
actions of non-human intelligences.

It’s really hard to imagine
aliens that are fundamentally different from human beings, which is why aliens
in movies (e.g. Star Trek) always
look pretty much like humans. People anthropomorphize evolution, AI and
fictional aliens because they fail to understand (or imagine) humanity as a unique
special case of intelligence. Not all intelligence requires looking or even
thinking like a human! If there are true alien species, they might be more
different from us than we are from insects, and they may feel emotions (if they
even have emotions) that our minds
cannot empathize with.
Your power as a mind is your ability to hit
small targets in a large search space – either the space of possible futures
(planning) or the space of possible designs (invention). Intelligence and
natural selection are meta-level processes of optimization, with technology and cats on the object-level as
outputs. We humans have invented science, but we have not yet redesigned the
protected, hidden meta-level structure of the human brain itself. Artificial
Intelligence (AI) that could rewrite its own machine code would be able to
recursively optimize the optimization structure itself – a historical first!
This “singularity” would therefore be far more powerful than calculations based
on human progress would suggest. The graph of “optimization power in” versus
“optimized product out” after a fully general AI is going to look completely
different from Earth’s history so far.
Students who take computer programming courses
often have the intuition that you can program a computer by telling it what to
do – literally, like writing “put these letters on the screen”. But the
computer isn’t going to understand you unless you program it to understand. Artificial
Intelligence can only do things that follow a lawful chain of cause-and-effect
starting at the programmer’s source code. It has no ghostly free will that you
can just tell what to do as if it were a human being. If you are programming an
AI, you aren’t giving instructions to a little ghost in the machine who looks
over the instructions and decides how to follow them; you are creating the ghost, because the program is the AI. If you have a program that
computes which decision the AI should make, you’re done. So, a Friendly AI cannot decide to just remove any
constraints you place on it.
Imagine that human beings had evolved a
built-in ability to count sheep, but had absolutely no idea how it worked.
These people would be stuck on the “artificial addition” (i.e. machine
calculator) problem, the way that people in our world currently are stuck on
artificial intelligence. In that world, philosophers would argue that
calculators only “simulated” addition rather than really adding. They would
take the same silly approaches, like trying to “evolve” an artificial adder or
invoking the need for special physics. All these methods dodge the crucial task
of understanding what addition
involves. The real history of AI teaches us that we should beware of assertions
that we can’t generate from our own knowledge, and that we shouldn’t dance
around confusing gaps in our knowledge. Until you know a clever idea will work, it won’t!
Instrumental
values (means) are different
from terminal values (ends), yet they
get confused in moral arguments. Terminal values are world states that we
assign some sort of positive or negative worth (utility) to. Instrumental values are links in a chain of events
that lead to desired world states. Our decisions are based on expected utilities of actions, which
depend on factual beliefs about the consequences (i.e. the probability of the
outcome conditional on taking the
action), and the utility of possible outcomes.
An ideal Bayesian decision system picks an action whose expected utility is
maximal. Many debates fail to distinguish between terminal and instrumental
values. People may share values (e.g. that crime is bad) but disagree about the
factual instrumental consequences of an action (e.g. banning guns).
Despite our need for closure, generalizations
are leaky. The words and statements we use at the macroscopic level are
inherently “leaky” because they do not precisely convey absolute and perfect
information. For example, most humans have ten fingers, but if you know that
someone is a human, that doesn’t guarantee that they have ten fingers. This
also applies to planning and ethical advice, like instrumental values (i.e.
expected utility). They often have no specification that is both compact
(simple) and local. Yet this
complexity of action doesn’t say much about the complexity of goals. If
expected utilities are leaky and complicated, it doesn’t mean that utilities (terminal values) must be
leaky and complicated as well. For example, we might say that killing anyone,
even Hitler, is bad. But the positive utility of saving many lives by shooting
Hitler can make the net expected utility positive.
There are a lot of things that humans care
about. Therefore, the wishes we make (as if to a genie) are enormously more
complicated than we would intuitively suspect. If you wish for your mother to “get
out of a burning building”, there are many paths through time and many roads
leading to that destination. For example, the building may explode and send her
flying through the air; she could fall from a second-story window; a rescue
worker may remove her body after the building finishes burning down, etc. Only
you know what you actually wanted. A wish is a leaky generalization: there is no safe genie except one who shares
your entire morality, especially your terminal values. Otherwise the genie may
take you to an unexpected (and undesirable) destination – a safe genie just does what it is you wish for (so you
might as well say, “I wish for you to do what I should wish for”).
Remember the tragedy of group selectionism:
evolution doesn’t listen to clever, persuasive arguments for why it will do
things the way you prefer, so don’t bother. The causal structure of natural
selection or AI is so different from your brain that it is an optimistic
fallacy to argue that they will necessarily produce a solution that ranks high
in your preference-ordering. Yet
people do this out of instinct, since their brains are black boxes, and we
evolved to argue politics. We tend not to bring to the surface candidate
strategies we know no person wants. But remember, different optimization
processes will search for possible solutions in different orders.
Civilization often loses sight of purpose
(terminal values). Various steps in a complex plan to achieve some desired goal
become valued in and of themselves, due to incentive structures. For example,
schools focus more on preparing for tests than instilling knowledge, because it
gives bureaucracy something to measure today. Such measures are often leaky
generalizations. The extreme case is Soviet shoe factories manufacturing tiny
shoes to meet their production quotas. Notice when you are still doing
something that has become disconnected from its original purpose.
›
14
|
A Human’s Guide to Words
|
This
chapter discusses the basic relationship between cognition and concept formation.
You may think that definitions can’t be “wrong”, but suboptimal use of
categories can have negative side effects on your cognition – like teaching
you the attitude of not admitting your mistakes.
|
In the Parable
of the Dagger (adapted from Raymond Smullyan), a court jester is shown two
boxes: one with the inscription “Either both inscriptions are true, or both
inscriptions are false” and another with “This box contains the key”. The
jester is told by the King that if he finds the key, he’ll be let free, but
that the other box contains a dagger for his heart. The jester tries to reason
logically that the second box must contain the key, but opens it to find a
dagger. The King explained: “I merely wrote those inscriptions on two boxes,
and then I put the dagger in the second one.” This tale illustrates how
self-referential sentences can fool you, since their truth value cannot be
empirically determined. It is a version of the liar paradox (i.e. “this sentence is a lie”). Words should connect
to reality – otherwise I could ask you: Is Socrates a framster? Yes or no?
Statements are only entangled with reality if the process generating them made
them so.
A standard syllogism goes: “All men are mortal.
Socrates is a man. Therefore Socrates is mortal.” But if you defined humans to not be mortal, would Socrates live
forever? No. You can’t make reality go a different way by choosing a different
definition. A logically valid syllogism is valid in all possible worlds, so it
doesn’t tell us which possible world
we actually live in. If you predict that Socrates would die if he drank
hemlock, this is an empirical proposition – it is not true “by definition”,
because there are logically possible worlds where Socrates may be immune to
hemlock due to some quirk of biochemistry. Logic can help us predict, but not
settle an empirical question. And if mortality is necessary to be “human” by
your definition, then you can never know for certain that Socrates is a “human”
until you observe him to be mortal – but you know perfectly well that he is
human.
Our brains make inferences quickly and
automatically – which is fine for recognizing tigers, but can cause you to make
philosophical mistakes. The mere presence of words can influence thinking,
sometimes misleading it. Labeling something can disguise a challengeable
inductive inference you are making. For example, defining humans as mortal
means you can’t classify someone as human until you observe their mortality.
Or, imagine finding a barrel with a hole large enough for a hand. If the last
11 small, curved egg-shaped objects drawn have been blue, and the last 8 hard,
flat cubes drawn have been red, it is a matter of induction to say that this
rule will hold in the future (it is not proven). But if you call the blue eggs
“bleggs” and the red cubes “rubes”, you may reach into the barrel, feel an egg
shape, and think “Oh, it’s a blegg”.
Definitions are maps, not treasure. They can be
intensional (referring to other
words) or extensional (pointing to
real-life examples). Ideally, the extension should match the intension, so you
shouldn’t define “Mars” as “The God of War” and simultaneously point to a red
light in the night sky and say “that’s Mars”. And you should avoid defining
words using ever-more-abstract words without being able to point to an example.
If someone asks “What is red?” it’s better to point to a stop sign and an apple
than to say, “Red is a color, and color is a property of a thing.” But the
brain applies intensions sub-deliberately, and you cannot capture in words all
the details of the cognitive concept as it exists in your mind. Thus you cannot
directly program the neural patterns of a concept into someone else’s brain;
hence why people have arguments over definitions.
Humans have too many things in common to list;
definitions like “featherless biped” are just clues that lead us to similarity clusters or properties that
can distinguish similarity clusters. Our psychology doesn’t follow Aristotelian
logical class definitions. If your verbal definition doesn’t capture more than
a tiny fraction of the category’s shared characteristics, don’t try to reason
as if it does. Otherwise you’ll be like the philosophers of Plato’s Academy who
claimed that the best definition of a human was a “featherless biped”,
whereupon Diogenes the Cynic is said to have exhibited a plucked chicken and
declared, “Here is Plato’s Man.” The Platonists then changed their definition
to “a featherless biped with broad nails.” Better would be to say, “See
Diogenes over there? That’s a human, and I’m a human, and you’re a human, and
that chimpanzee is not, though fairly close.”
Cognitive psychology experiments have found
that people think that pigeons and robins are more “typical birds” than
penguins and ducks (due to typicality effects
or prototype effects), and that 98 is
closer to 100 than 100 is to 98. Interestingly, a between-groups experiment
showed that subjects thought a disease was more likely to spread from robins to
ducks on an island, than from ducks to robins. Likewise, Americans seem to
reason as if closeness is an inherent property of Kansas and distance is an
inherent property of Alaska, and thus that Kansas is closer to Alaska than
Alaska is to Kansas. Aristotelian categories (true-or-false membership) aren’t
even good ways of modeling human psychology! Category membership is not
all-or-nothing; there are more or less typical subclusters.
Objects have positions in configuration space, along all relevant dimensions (e.g. mass,
volume). The position of an object’s point in this space corresponds to all the
information in the real object itself. Concepts roughly describe clusters in thingspace. Categories may radiate a
glow: an empirical cluster may have no set of necessary and sufficient
properties, so definitions cannot exactly match them. The map is smaller and
much less complicated than the territory. In practice, a verbal definition may
work well enough to point out the intended cluster of similar things, in which
case you shouldn’t nitpick exceptions. If you look for the empirical cluster of
“has ten fingers, wears clothes, uses language”, then you’ll get enough
information that the occasional nine-fingered human won’t fool you.
Questions may represent different queries on
different occasions, and definitional disputes are about whether to infer a characteristic
shared by most things in an empirical cluster. But a dictionary can’t move the
actual points in Thingspace. Is atheism a “religion”? Regardless of what the
dictionary says, the disguised query is
about whether the empirical cluster of atheists use the same reasoning methods
(or violence) used in religion. It is problematic when you ask whether
something “is” or “is not” a category member but can’t name the question you
really want answered. For example, what is a “man”, and is Barney the Baby Boy
a “man”? The “correct” answer may depend considerably on whether the query you really want answered is “Would hemlock
be a good thing to feed Barney?” or “Will Barney make a good husband?”
Our brains probably use a fast, cheap and
scalable neural network design, with
a central node for a category (e.g. “human”). Thus we associate humans with
wearing clothes and being mortal, but it’s less intuitive to connect clothes
with mortality. This design is visualized in the following figure:

We intuitively perceive
hierarchical categories, but it’s a mistake to treat them like the only correct
way to analyze the world, because other forms of statistical inference are
possible (even though our brains don’t use them). For example, compare the
following two networks:

A human might easily notice whether an object is a “blegg” or a “rube”,
but not that red furred objects which never glow in the dark have all the other
characteristics of bleggs. Other statistical algorithms (like the network on
the right) work differently.
Our cognitive design means that even after we
know all the surrounding nodes, the central node may still be unactivated –
thus we feel as if there is a leftover question. This is what our brain’s
algorithm feels like from inside. To fix your errors, you must realize that
your mind’s eye is looking at your intuitions,
not at reality directly. Categories are inferences implemented in a real brain,
not manna fallen from the Platonic Realm. One example of a mistake is when you
argue about a category membership even after screening off all questions that
could possibly depend on a category-based inference. After you observe that an
object is blue, egg-shaped, furred, flexible, opaque, luminescent, and
palladium-containing, there’s nothing left
to ask by arguing “Is it a blegg?” even if it may still feel like there’s a leftover question.
If a tree falls in a deserted forest, does it
make a sound? The word “sound” can refer to auditory experiences in a brain, or
acoustic vibrations in the air, and two disputants would probably agree about
what is actually going on inside the forest. But even after knowing that the
falling tree creates acoustic vibrations but not auditory experiences, it feels like there’s a leftover question.
So they argue about definitions, even though dictionary editors are mere
historians of usage, not legislators of language. Oftentimes, the definition of
a word becomes politically charged only after the argument has started. Don’t
allow an argument to slide into being about definitions if it isn’t what you
originally wanted to argue about. It may help to keep track of some testable
proposition that the argument is actually about, and to avoid using the word
that’s causing problems. Remember that anything which is true “by definition”
is true in all possible worlds, so observing its truth can never constrain which world you live in.
For evolutionary reasons, the complexity of
communication is hidden from us (because fast transmission of thoughts is
crucial in times of danger, like when there is a tiger around). So we
intuitively feel like the label or word and its meaning (concept) are
identical, or that the meaning is an intrinsic property of the word. Hence
disputing definitions feels like disputing facts, and people want to find the correct meaning of a label like “sound”.
But meaning is not a property of the word itself; there is just a label that
your brain associates to a particular concept.
Language relies on coordination to work, so we
have a mutual interest in using the same words for similar concepts. When each
side understands what’s in the other’s mind, you’re done – in that case there’s no need to argue over the meanings of a
word. If you defy common usage without reason, you make it gratuitously hard
for people to understand you. People who
argue definitions often aren’t trying to communicate, but to infer an empirical
or moral proposition. Yet dictionaries can’t settle such queries, as dictionary
editors are not legislators of language and don’t have ultimate wisdom on
substantive issues. If the common definition contains a problem (e.g. if
“dolphin” is defined as a kind of fish), the dictionary will reflect the
standard mistake. Do not pull out a dictionary in the middle of an empirical or
moral argument, or any argument ever!
People use complex renaming to create the
illusion of inference; e.g. “a ‘human’ is a ‘mortal featherless biped’”. But when
you replace words with their definitions, Aristotelian syllogisms look less
impressive. We would write: “All [mortal featherless bipeds] are mortal;
Socrates is a [mortal featherless biped]; therefore Socrates is mortal.” That
is because they are empirically unhelpful, and the labels merely conceal the
premises and pretend to novelty in the conclusion. If you define a word rigidly
in terms of attributes and state that something is that word, you assert that
it has all those attributes; if you then go on to say it thus has one of those
attributes, you are simply repeating that assertion. People think they can
define a word any way they like, but a better proverb is: definitions don’t
need words.
In the game Taboo
by Hasbro, the player tries to get their partner to guess a word on a card
without using that word or five additional words listed on the card. If you
play Rationalist’s Taboo on a word
and its close synonyms (i.e. thinking without using those words), you will
reveal which expectations you anticipate, and reduce philosophical difficulties
and disputes. It will help you describe outward observables and interior
mechanisms, without using handles. It works better than trying to define your
problematic terms. For example, eliminating the word “sound” can avoid the
argument between two people about whether a tree falling in a forest produces a
sound if nobody hears it.
The existence of a neat little word can prevent
you from seeing the details of the thing you are trying to think about. What
actually goes on in schools once you stop calling it “education”? Using Rationalist’s Taboo involves visualizing
the details and hugging the query. Since categories can throw away information
or lead to lost purpose (e.g. conflating a degree for learning), the fix is to
replace the symbol with the substance. In other words: replace the word with
the meaning, the label with the concept, the signifier with the signified; and
dereference the pointer. Zoom in on your map.
The map is not the territory, but you can’t
fold up the territory and put it in your glove compartment. Our map inevitably
compresses reality, causing things that are distinct to feel like one point.
Thus you may end up using one word when there are two or more different
things-in-reality, and dump all the facts about them into a single
undifferentiated mental bucket (e.g. using the word “consciousness” to refer to
being awake and reflectivity). You
may not even know that two distinct entities exist! Expanding the map is a
scientific challenge, but sometimes using words wisely can help to allocate the
right amount of mental buckets. A good hint is noticing a category with
self-contradictory attributes.
The Japanese have a theory of personality based
on blood types; people with blood type A are earnest and creative while those
with type B are wild and cheerful, for example. This illustrates how we can
make up stuff and see illusory patterns as soon as we name the category. Once
you draw a boundary around a group, the mind starts trying to harvest
similarities from it. Our brains detect patterns whether they are there or not.
It’s just how our neural algorithms work – thus categorizing has consequences!
One more reason not to believe that you can define a word any way you like.
We use words to infer the unobserved from the
observed, and this can sneak in many connotations.
These characteristics usually aren’t listed in the dictionary, implying that
people argue because they care about the connotation, not the dictionary
definition. For example, suppose the dictionary defines a “wiggin” as a person
with green eyes and black hair. If “wiggin” also carries the connotation of
someone who commits crime, but this part isn’t in the dictionary, then saying
“See, I told you he’s a wiggin! Watch what he steals next…” is sneaking in the
connotation.
Disputes are rarely about visible, known, and
widely-believed characteristics, but usually about sneaking in connotations
when the subject arguably differs from an empirical similarity cluster. For
example, some declare that “atheism is a religion by definition!” But you
cannot establish membership in an empirical cluster by definition; atheism does
not resemble the central members of the “religion” cluster. When people insist
that something is “true by definition”, it’s usually when there is other
information that calls the default inference into doubt.
It may feel
like a word has a meaning that you can discover by finding the right
definition, but it is not so. The real challenge of categorization is figuring
out which things are clustered together, and to carve reality along its natural
joints. Both intensional and extensional definitions can be “wrong” if they
fail to do so. For example, dolphins are not fish, because they don’t belong
together with salmon and trout. Drawing the right boundary in thingspace is a scientific challenge
(not the job of dictionary editors). Which concepts usefully divide the world
is a question about the world. And you should be able to admit when your
definition-guesses are mistaken.
A good code transmits messages quickly by
reserving short words for words used frequently. The theoretical optimum
(according to the Minimum Description
Length formalization of Occam’s Razor) is to have the length of the message
you need to describe something correspond exactly to its probability. The
labels or sounds we attach to concepts aren’t arbitrary! Humans tend to use basic-level categories (e.g. “chair”)
more than specific ones (e.g. “recliner”). If you use a short word for
something you won’t need to describe often or a long word for something you
will, the result is inefficient thinking or even a misapplication of Occam’s
Razor if your mind thinks that short sentences sound “simpler”. For instance,
“God did a miracle” sounds more plausible than “a supernatural
universe-creating entity temporarily suspended the laws of physics.”
When two variables are entangled, such that
P(Z, Y) > P(Z)*P(Y), they have mutual
information. This means that one is Bayesian evidence about the other.
Words are wrong when some of the thing’s properties don’t help us do
probabilistic inference about the others. The way to carve reality at its
joints is to draw your boundaries around concentrations of unusually high
probability density in Thingspace. So if green-eyed people are not more likely
to have black hair, or vice versa, and they don’t share any other characteristics
in common, why have a word for “wiggin”?
A concept is any rule for classifying things. The
conceptspace of definable rules that
include or exclude examples is exponentially larger than thingspace (the space of describable things),
because the space of all possible concepts grows superexponentially in the
number of attributes. Thus, learning is inductive
bias that requires us to use highly regular concepts and draw simple
boundaries around high probability-density concentrations. Don’t draw an
unsimple boundary without any reason to do so. It would be suspicious if you
defined a word to refer to all humans except black people. If you don’t present
reasons to draw that particular boundary, raising it to the level of our
deliberate attention is like a detective saying, “Well, I haven’t the slightest
shred of support one way or the other for who could’ve murdered those orphans…
but have we considered John Q. Wiffleheim of 1234 Norkle Road as a suspect?”
In a system with three perfectly correlated
variables, learning Z can render X and Y conditionally
independent. Likewise, a neural network can use a central variable to
screen off the others from each other to simplify the math: this is called Naïve Bayes. If you want to use
categorization to make inferences about properties, you need the appropriate
empirical structure, which is conditional independence given knowledge of the
class (to be well-approximated by Naïve Bayes). For example, if the central
class variable is “human”, then we can predict the probabilities of the thing
having ten fingers, speaking, and wearing clothes – but these are all
independent (so just because a person is missing a finger doesn’t make them
more likely to be a nudist than the next person). This Bayesian structure
applies to many AI algorithms.
Visualize a “triangular lightbulb”. What did
you see? Can you visualize a “green dog”? Your brain can visualize images, and
words are like paintbrush handles which we use to draw pictures of concepts in
each other’s minds. The mental image is more complex and detailed than the word
itself or the sound in the air. Words are labels that point to things/concepts. Words are not like tiny little LISP symbols in your mind. When you are handed
a pointer, sooner or later you have to dereference it and actually look in the
relevant memory area to see what the word points to.
Sentences may contain hidden speaker-dependent
or context-dependent variables, which can make reality seem protean, shifting
and unstable. This illusion may happen especially when you use a word that has
different meanings in different places as though it meant the same thing on
each occasion. For example, “Martin told Bob the building was on his left” –
but whose “left”, Bob’s or Martin’s? The function-word “left” evaluates with a
speaker-dependent variable grabbed from the surrounding context. Remember that
your mind’s eye sees the map, not the territory directly.
Using words unwisely or suboptimally can
adversely affect your cognition, since your mind races ahead unconsciously
without your supervision. Therefore you shouldn’t think that you can define a
word any way you like. In practice, saying “there’s no way my choice of X can
be ‘wrong’” is nearly always an error, because you can always be wrong.
Everything you do in the mind has an effect. You wouldn’t drive a car over thin
ice with the accelerator floored and say “Looking at this steering wheel, I
can’t see why one radial angle is special – so I can turn the steering wheel
any way I like.”
›
Interlude: An Intuitive Explanation of Bayes’s
Theorem
THIS ESSAY FROM Yudkowsky’s website gently introduces Bayesian inference. If you
look up “Bayes’s Theorem” or “Bayes’s Rule”, you’ll find a random statistical
equation and wonder why it’s useful or why your friends and colleagues sound so
enthusiastic about it. Soon you will know.
To begin, here’s a situation that doctors often encounter: 1% of women at age forty who
participate in routine screening have breast cancer. 80% of women with breast
cancer will get positive mammographies, but 9.6% of women without breast cancer
will also get positive mammographies. A woman in this age group had a positive
mammography in a routine screening. What is the probability that she actually
has breast cancer? What do you think the answer is? Surprisingly, most doctors
get the same wrong answer on this problem!
Studies find that most doctors estimate the probability to be between 70% and 80%, which
is incorrect. To get the correct answer, suppose that 100 out of 10,000 women
(1%) have breast cancer and 9,900 do not. From the group of 100, 80 will have a
positive mammography. From the group of 9,900 about 950 will also have a
positive mammography. So the total number of women with positive mammographies
is 950 + 80 = 1,030. Of these 1030 women, 80 will have breast cancer. As a
proportion, this is 80/1030 = 0.07767 = 7.77% or approximately 7.8%. This is
the correct answer.
Figuring out the final answer requires three pieces of information: the original percentage of women with
breast cancer (the prior probability);
the percentage of women without breast cancer who receive false positives; and
the percentage of women with breast cancer who receive true positives. The last
two are known as conditional
probabilities. All of this initial information is collectively known as the
priors. The final answer is known as
the revised probability or posterior probability, and as we have
just seen, it depends in part on the prior probability.
To see why you always need all three pieces of information, imagine an alternate
universe where only one woman out of a million has breast cancer. If a
mammography gave a true positive result in 8 out of 10 cases and had a false
positive rate of 10%, then the initial probability that a woman has breast
cancer is so incredibly low that even if she gets a positive result, it’s still
probably the case that she does not have breast cancer (because there are a lot
more women getting false positives than true positives). Thus, the new evidence
you get from the mammography does not replace
the data you had at the outset, but merely slides
the probability in one direction or the other from that starting point. And if
someone is equally likely to get the same test result regardless of whether or
not she has cancer, then the test doesn’t tell us anything, and we don’t shift
our probability.
Now suppose a barrel contains many small plastic eggs, some red and some blue. If 40% of
the eggs contain pearls and 60% contain nothing, we can write P(pearl) = 40%.
Furthermore, if 30% of the eggs containing pearls are painted blue and 10% of
the eggs containing nothing are painted blue, we can write P(blue|pearl) = 30%
which means “the probability of blue given
pearl”, and P(blue|~pearl) = 10% which means “the probability that an egg is
painted blue, given that the egg does not
contain a pearl”. What is the probability that a blue egg contains a pearl? In
other words, P(pearl|blue) = ?
If 40% of eggs contain pearls and 30% of those are painted blue, then the fraction of
all eggs that are blue and contain
pearls is 12%. If 10% of the 60% of eggs containing nothing are painted blue,
then 6% of all the eggs contain nothing and are painted blue. So 12% + 6% = 18%
of eggs are blue. Therefore the chance a blue egg contains a pearl is 12/18 =
2/3 = 67%. Without Bayesian reasoning, one might respond that the probability a
blue egg contains a pearl is 30% or maybe 20% (by subtracting the false
positive rate). But that makes no sense in terms of the question asked.
It might help to visualize
what is going on here. In the following graphic, the bar at
the top is measuring all eggs, both
blue and red; while the bottom bar is measuring only blue eggs. You can see how the prior probability and two
conditional probabilities determine the posterior.

If we grab an egg from the bin
and see that it is blue, and if we know that the chances it would be
blue if it had a pearl are higher than the chances it would be blue if it didn’t have a pearl, then we slide our
probability that the egg contains a pearl in the upward direction.
Studies find that people do better on these problems when they are
phrased as natural frequencies (i.e.
absolute numbers like “400 out of 1000 eggs”) rather than percentages or
probabilities. A visualization in terms of natural frequencies might look like
this:

Here you can see that the collection of all eggs is larger than the collection of just blue
eggs, and you can see that the pearl
condition takes up a larger proportion of the bottom bar than it does in the
top bar, which means we are updating our probability upward.
The quantity P(A,B) is the same as P(B,A) but P(A|B) is not the same thing as P(B|A) and P(A,B) is completely different
from P(A|B). The probability that a patient has breast cancer and a positive mammography is
P(positive, cancer) which we can find by multiplying the fraction of patients
with cancer P(cancer) and the chance that a cancer patient has a positive
mammography P(positive|cancer). These three variables share two degrees of
freedom among them, because if we know any two, we can deduce the third.
E.T. Jaynes suggested that credibility and evidence should be measured in decibels, which is given by 10*log10(intensity).
Suppose we start with a 1% prior probability that a woman has breast cancer.
This can be expressed as an odds ratio
of 1:99. Now we administer three independent tests for breast cancer. The
probability that a test gives a true positive divided by the probability that
it gives a false positive is known as the likelihood
ratio of that test. Let’s say the likelihood ratios for the three tests are
25:3, 18:1 and 7:2 respectively. We can multiply the numbers to get the odds
for women with breast cancer who score positive on all three tests versus women
without breast cancer who score positive on all three tests: 1*25*18*7 :
99*3*1*2 = 3150:594. To convert the odds back into probabilities, we just write
3150/(3150+594) = 84%.
Alternatively, you could just add the logarithms. We start out with
10*log10(1/99) = -20 decibels for our credibility that a woman has
breast cancer, which is fairly low. But then the three test results come in,
corresponding to 10*log10(25/3) = 9 decibels of evidence for the
first test, 13 for the second and 5 for the third. This raises the credibility
level by a total of 27 decibels, which shifts the prior credibility from -20
decibels to a posterior credibility of 7 decibels, so the odds go from 1:99 to
5:1 and the probability goes from 1% to around 83%.
To find the probability that a
woman with a positive mammography has breast cancer, or
P(cancer|positive), we computed P(positive, cancer)/P(positive), which is
which is the same as
which in its general form is known as
Bayes’s Theorem or Bayes’s Rule.
When there is some phenomenon A we want
to investigate, and some observation X that is evidence about A, Bayes’s
Theorem tells us how we should update
our probability of A given the new
evidence X. The formula describes what makes something “evidence” and how
much evidence it is. In cognitive science, a rational mind is a Bayesian
reasoner. In statistics, models are judged by comparison to the Bayesian
method. There is even the idea that science itself is a special case of Bayes’s
Theorem, because experimental evidence is Bayesian evidence.
The Bayesian revolution in the sciences
is currently replacing Karl Popper’s philosophy of falsificationism. If your theory makes a definite prediction that
P(X|A) ≈ 1 then observing ~X
strongly falsifies A, whereas observing X does not definitely confirm the
theory because there might be some other condition B such that P(X|B) ≈ 1. It is a Bayesian
rule that falsification is much stronger than confirmation – but falsification
is still probabilistic in nature, and Popper’s idea that there is no such thing
as confirmation is incorrect.
This is Bayes’s Theorem:
On the left side of the equation, X is
the evidence we’re using to make inferences about A. Think of it as the degree
to which X implies A. In other words, P(A|X) is the proportion of things that
have property A and property X among all
things that have A; e.g. the proportion of women with breast cancer and a
positive mammography within the group of all women with positive mammographies.
In a sense, P(A|X) really means P(A,X|X) but since you already know it has
property X, specifying the extra X all the time would be redundant. When you
take property X as a given, and restrict your focus to within this group, then
looking for P(A|X) is the same as looking for just P(A).
The right side of Bayes’s Theorem is
derived from the left side since P(A|X) = P(X,A)/P(X). The implication when we reason about causal relations is that facts
cause observations, e.g. that breast cancer causes positive mammography
results. So when we observe a positive mammography, we infer an increased probability of breast cancer, written
P(cancer|positive) on the left side of the equation. Symmetrically, the right
side of the equation describes the elementary causal steps, so they take the
form P(positive|cancer) or P(positive|~cancer). So that is Bayes’s Theorem.
Rational inference (mind) on one side is
bound to physical causality (reality) on the other.
Reverend Thomas Bayes welcomes you to the
Bayesian Conspiracy.
›

Comments
Post a Comment